


Avazu(艾維邑動(dòng))是一家集PC和移動(dòng)互聯(lián)網(wǎng)廣告全球投放,全球?qū)I(yè)移動(dòng)游戲運(yùn)營(yíng)及發(fā)行的技術(shù)型公司。為了給客戶提供最好的廣告效果,公司自主研發(fā)的DSP平臺(tái)使用了最前沿的機(jī)器學(xué)習(xí)算法,下面就來介紹一下相關(guān)的廣告優(yōu)化原理和機(jī)器學(xué)習(xí)算法。
廣告優(yōu)化
眾所周知,廣告點(diǎn)擊率(CTR)和轉(zhuǎn)化率(CR)代表了廣告投放的效果,如何提高CTR和CR是每個(gè)廣告主都十分關(guān)心的問題。Avazu通過機(jī)器學(xué)習(xí)算法,自動(dòng)地為實(shí)時(shí)流量預(yù)估CTR,廣告主只需簡(jiǎn)單的將優(yōu)化目標(biāo)設(shè)置為期望CTR,DSP投放引擎即可為廣告主購(gòu)買相應(yīng)的優(yōu)質(zhì)流量,完成這一任務(wù)。如廣告主設(shè)置優(yōu)化目標(biāo)為CPC,則投放引擎通過將CPC轉(zhuǎn)化為期望CPM(CPM = CTR * 1000 * CPC),購(gòu)買對(duì)應(yīng)價(jià)格的流量。所以機(jī)器學(xué)習(xí)預(yù)測(cè)越準(zhǔn),廣告優(yōu)化效果就越好。
機(jī)器學(xué)習(xí)
機(jī)器學(xué)習(xí)是一類從數(shù)據(jù)中自動(dòng)分析獲得規(guī)律,并利用規(guī)律對(duì)未知數(shù)據(jù)進(jìn)行預(yù)測(cè)的算法。由于互聯(lián)網(wǎng)行業(yè)的數(shù)據(jù)規(guī)模已超過人工分析能力之所及,機(jī)器學(xué)習(xí)技術(shù)幾乎成為每家互聯(lián)網(wǎng)公司的標(biāo)配,在搜索排序,商品排序,點(diǎn)擊率預(yù)估,反作弊,實(shí)時(shí)競(jìng)價(jià)等各種領(lǐng)域有著廣泛的應(yīng)用。
Avazu的機(jī)器學(xué)習(xí)平臺(tái)最主要的算法包括邏輯回歸、隨機(jī)森林、深度學(xué)習(xí),這里我們介紹邏輯回歸和深度學(xué)習(xí)。
邏輯回歸
概述
邏輯回歸(Logistic Regression)是線性模型的一種,歷史悠久,廣泛應(yīng)用于各種分類任務(wù),尤其在互聯(lián)網(wǎng)廣告行業(yè)中,已成為點(diǎn)擊率預(yù)估的基準(zhǔn)方法。
二分類邏輯回歸的預(yù)測(cè)公式形如
p(=1|) = 1 / (1+)
p(=-1|) = / (1+)
其中,為數(shù)據(jù)特征,為模型參數(shù),為分類目標(biāo),p(=1|)即預(yù)測(cè)為1的概率,在廣告點(diǎn)擊率預(yù)估中即為點(diǎn)擊的概率。對(duì)模型預(yù)測(cè)的y值和真實(shí)y值建立的損失函數(shù)E為L(zhǎng)ogLoss,形如
E =
最小化損失函數(shù)可使預(yù)測(cè)值與真實(shí)值差異最小。為控制模型過擬合,可以為損失函數(shù)加上正則項(xiàng),常見的正則項(xiàng)包括w的2范數(shù)或1范數(shù),即
E = + λ
其中為w的2范數(shù),λ為超參數(shù),需要通過交叉驗(yàn)證(cross-validation)選取。
訓(xùn)練方法
我們可以通過一些最優(yōu)化(Optimization)算法來最小化損失函數(shù),常見的最優(yōu)化方法有隨機(jī)梯度下降(SGD)和L-BFGS等。
SGD是一種在線(online)算法,其特點(diǎn)是每次更新模型只使用少量隨機(jī)數(shù)據(jù)(通常為一個(gè)樣本),因此訓(xùn)練速度很快。SGD的更新方法形如
= –
其中,為損失函數(shù)E對(duì)的梯度,為梯度下降的步長(zhǎng)。對(duì)于步長(zhǎng)有很多研究,一種常見的設(shè)計(jì)為
= / (1 + λt)
由于SGD的隨機(jī)性,其收斂速度和質(zhì)量不是最好,可能需要迭代幾十輪(遍歷整個(gè)數(shù)據(jù)集的次數(shù))。
L-BFGS則是一種batch算法,與online算法相反,每次更新模型都使用整個(gè)數(shù)據(jù)集,因此訓(xùn)練速度較慢,但模型收斂穩(wěn)定,預(yù)測(cè)質(zhì)量好于SGD。
對(duì)于廣告行業(yè)來說,由于數(shù)據(jù)具有冗余性(即在整個(gè)數(shù)據(jù)集中,相同的記錄會(huì)出現(xiàn)多次),所以以L-BFGS為代表的batch算法在一次迭代中做了很多重復(fù)計(jì)算,因此SGD在大數(shù)據(jù)集上更受歡迎。也可以在迭代的前幾輪使用SGD,以較小的代價(jià)求得一個(gè)較好的解,再用L-BFGS繼續(xù)訓(xùn)練,得到更好更穩(wěn)定的解。
在大數(shù)據(jù)背景下,算法通常需要并行化。一種常見的策略是將數(shù)據(jù)隨機(jī)分成多份,每份數(shù)據(jù)各自訓(xùn)練獨(dú)立的模型,最后將多個(gè)模型的參數(shù)按一定的加權(quán)辦法融合平均。其他并行/分布式訓(xùn)練策略還有很多,在此不一一贅述。
稀疏數(shù)據(jù)
互聯(lián)網(wǎng)廣告行業(yè)的數(shù)據(jù)通產(chǎn)被稱為“稀疏數(shù)據(jù)”,即一行記錄只包含少量特征。舉例來說,如果我們有n個(gè)廣告商,那么整個(gè)模型關(guān)于廣告商的特征有n個(gè),而一次曝光只含有一個(gè)廣告商,則該曝光該廣告商特征取值1,其他廣告商特征取值0。這種特征處理方式被稱為1-hot編碼。對(duì)于0值我們不做記錄也不做處理,因此稱為稀疏數(shù)據(jù)。
特征編碼與個(gè)性化
如前所述,我們對(duì)所有的特征都進(jìn)行1-hot編碼,由于每個(gè)特征的編碼集大小動(dòng)態(tài)變化(比如加入了新的廣告商),使得模型訓(xùn)練頗為不便,所以我們使用hash方法將特征映射到固定大小的編碼集上。比如說,對(duì)設(shè)備這個(gè)特征,以二元組<“設(shè)備”,設(shè)備ID>進(jìn)行hash,得到值1024,則將映射特征1024的取值為1。同時(shí),我們還可以組成特征三元組,如<廣告商ID,“設(shè)備”,設(shè)備ID>,hash以后的特征對(duì)于每個(gè)廣告商不盡相同,則訓(xùn)練出來的模型可視為廣告商個(gè)性化投放模型。
使用hash方法給特征編碼,相對(duì)于使用字典編碼,速度非常快,并且特征和模型參數(shù)也是固定的。

實(shí)驗(yàn)和分析
上圖為使用一個(gè)月的Avazu日志數(shù)據(jù)訓(xùn)練個(gè)性化邏輯回歸(以三元組hash編碼的形式實(shí)現(xiàn),圖中x坐標(biāo)軸為hash bit數(shù))與非個(gè)性化邏輯回歸的CTR預(yù)估誤差(相對(duì)值)對(duì)比。我們可以看到,個(gè)性化模型大大提高了CTR預(yù)估的準(zhǔn)確性。
深度學(xué)習(xí)
概述
深度學(xué)習(xí)(Deep Learning)是神經(jīng)網(wǎng)絡(luò)的一種,即層數(shù)很多的神經(jīng)網(wǎng)絡(luò),其概念由Hinton于2006年提出,成為近年來神經(jīng)網(wǎng)絡(luò)復(fù)興的標(biāo)志。
深度學(xué)習(xí)的成功,最初來自于微軟研究院在語音識(shí)別上的突破,而后由Hinton帶領(lǐng)的小組在圖像識(shí)別任務(wù)上取得了驚人成果。
深度學(xué)習(xí)的這股熱潮,在國(guó)內(nèi)機(jī)器學(xué)習(xí)業(yè)界幾乎無人不談,目前幾大互聯(lián)網(wǎng)公司均在嘗試,其成果以百度深度學(xué)習(xí)研究院最為突出,但應(yīng)用于廣告領(lǐng)域,國(guó)內(nèi)外尚未見大量成功案例的報(bào)道。
訓(xùn)練方法
傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)通常只有3層(輸入層、隱層、輸出層),因多層神經(jīng)網(wǎng)絡(luò)訓(xùn)練時(shí)會(huì)遇到所謂梯度消散(vanishing gradient)的問題,故并不成功,直到2006年,Hinton提出了逐層預(yù)訓(xùn)練(layer-wise pre-training)的方法才得以改善。后在2010年由James Martens提出一種Hessian-free方法使得深度學(xué)習(xí)不再需要預(yù)訓(xùn)練,大為簡(jiǎn)化。
如今的深度學(xué)習(xí)算法,回到了80年代發(fā)明的反向傳播算法,以超大的數(shù)據(jù)量,億萬級(jí)別的參數(shù),超長(zhǎng)的訓(xùn)練時(shí)間來彌補(bǔ)算法的不足。下面就簡(jiǎn)述一下反向傳播算法。
假設(shè)每一層的網(wǎng)絡(luò),為如下形式
=
=
其中X為輸入層,Y為輸出層,n和n-1為層的標(biāo)號(hào),F(xiàn)為激勵(lì)函數(shù),W則是模型的參數(shù)。
激勵(lì)函數(shù)的目的是使得神經(jīng)網(wǎng)絡(luò)非線性化,否則多層的線性變換會(huì)退化為單層線性變換,也就失去意義了,常見的激勵(lì)函數(shù)包括sigmoid、tanh等。
由此,我們可以使用前向傳播算法,由下一層的輸入X求出上一層的輸出Y,而由Y的激勵(lì)函數(shù)F求
出更上一層的輸入X,直至最上層的Y。
現(xiàn)在定義某種形式的損失函數(shù)E,對(duì)其求偏導(dǎo),根據(jù)鏈?zhǔn)角髮?dǎo)法則,有

現(xiàn)在,我們可以使用反向傳播算法,由上一層輸入X的偏導(dǎo)求出該層輸出Y的偏導(dǎo),而由Y的偏導(dǎo)求出該層W和下一層輸入X的偏導(dǎo),直至最下層的W。
算出了每一層的梯度以后,就可以使用梯度下降之類的優(yōu)化算法更新模型參數(shù)W。針對(duì)大數(shù)據(jù),深度學(xué)習(xí)通常采用mini-batch的更新方法,即每次使用128或256個(gè)樣本的梯度信息更新模型。
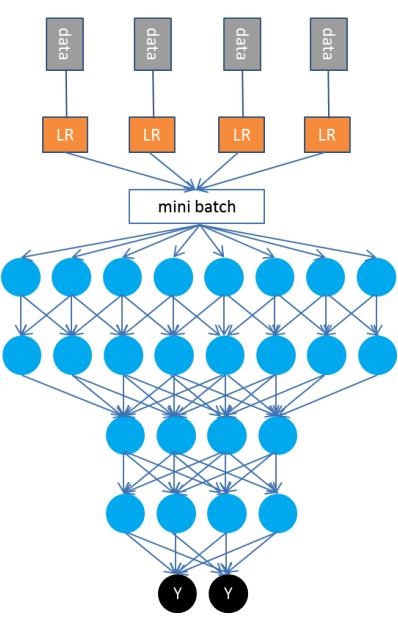
廣告數(shù)據(jù)
實(shí)際上深度學(xué)習(xí)并不能直接應(yīng)用于廣告領(lǐng)域建模,因?yàn)槿缜八觯瑥V告數(shù)據(jù)是稀疏數(shù)據(jù),而深度學(xué)習(xí)主要是矩陣運(yùn)算,是針對(duì)稠密數(shù)據(jù)的算法。所以我們對(duì)第一層采用了預(yù)訓(xùn)練的方法。具體如下:第一層依然使用邏輯回歸(LR)的并行訓(xùn)練算法,每個(gè)線程使用SGD訓(xùn)練自己的數(shù)據(jù)。模型接近收斂以后不做加權(quán)平均,轉(zhuǎn)而將多個(gè)模型輸出作為深度學(xué)習(xí)(DL)的輸入,訓(xùn)練一個(gè)深度神經(jīng)網(wǎng)絡(luò)。
顯然,邏輯回歸的輸出是一個(gè)稠密向量(如果有16個(gè)線程訓(xùn)練,那就會(huì)輸出一個(gè)16維的向量),所有樣本的輸出則形成一個(gè)大矩陣,取其mini-batch適合于訓(xùn)練深度學(xué)習(xí)模型。
實(shí)驗(yàn)和分析
我們?cè)俅问褂靡粋€(gè)月的日志數(shù)據(jù)分別訓(xùn)練了邏輯回歸模型和深度學(xué)習(xí)模型(都使用個(gè)性化hash),并欣喜的發(fā)現(xiàn),深度學(xué)習(xí)對(duì)點(diǎn)擊率預(yù)估的錯(cuò)誤率(以RMSE衡量)相對(duì)于邏輯回歸降低了6%之多。
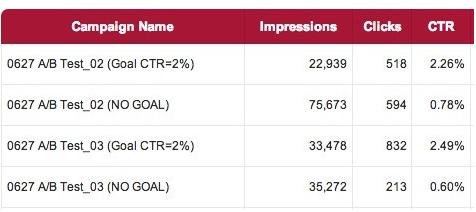
上圖為設(shè)定CTR目標(biāo)前后的實(shí)際投放測(cè)試效果對(duì)比,可見使用深度學(xué)習(xí)后,DSP投放引擎將自動(dòng)選擇符合目標(biāo)的優(yōu)質(zhì)流量。
對(duì)于深度學(xué)習(xí)的提升作用,我們認(rèn)為可能出于以下原因:
1. 邏輯回歸每個(gè)線程只訓(xùn)練自己的數(shù)據(jù),而深度學(xué)習(xí)則看到了所有的數(shù)據(jù)。
2. 邏輯回歸最終模型加權(quán)方式是人工指定的,而深度學(xué)習(xí)則使用了一個(gè)復(fù)雜的深度神經(jīng)網(wǎng)絡(luò)來進(jìn)行融合。
深度學(xué)習(xí)的缺點(diǎn)在于需要保留n份邏輯回歸模型,其預(yù)測(cè)耗時(shí)相比邏輯回歸增加了許多,所幸邏輯回歸本身計(jì)算速度非常快。
小結(jié)
Avazu DSP的機(jī)器學(xué)習(xí)技術(shù),將廣告投放的優(yōu)化工作簡(jiǎn)化為算法自動(dòng)優(yōu)化。在個(gè)性化邏輯回歸的基礎(chǔ)上,新開發(fā)的深度學(xué)習(xí)算法又有大幅提升。那么,深度學(xué)習(xí)在廣告行業(yè)是否還有更合適的訓(xùn)練方法,能否取得更好的效果?Avazu還將繼續(xù)探索。